
はじめに
Wallet Station管理画面のリメイクと、このブログの運営を担当している山根 正大です!
山根のいるチームでは、自分たちで作った機能に対して2023年2月頃から5月末まで、性能試験および改善を行っていました。
今回の記事はその振り返り記事となります。
山根自身、計画段階から性能試験を行うのは初めてだったのもあり、性能数値の考え方や、SQLチューニング時のお作法について沢山学びを得ることができました。
少しでも「性能試験、苦手だよ〜」という方の参考になればと思い、記載していきます!
管理画面リメイクとは?
山根が居るチームでは、2022年4月頃から、以下のミッションを掲げながら開発を進めてきました。
- 保守性向上のため、既存管理画面を新しいアーキテクチャに置き換える
- 新規にキャンペーン機能と集計機能を開発する
インフキュリオンでは、この管理画面を新しいアーキテクチャに置き換えていくプロジェクトを、「管理画面リメイク」と呼んでいます。
※アーキテクチャの置き換えを行うことになった詳しい経緯については、以下の記事も参照ください!
Wallet Station管理画面について

Wallet Stationは、オリジナルPayの構築・運営に必要な機能をワンストップで提供しています。
その中でも管理画面では、以下のような機能を提供します。
- ウォレットサービス(オリジナルPay)の管理
- オリジナルPayのユーザの管理
- 加盟店(オリジナルPayが利用できる店舗)の管理
- 取引履歴の管理・集計機能
- キャンペーンなど、販売促進機能
より詳細な情報についてはこちらのコーポレートサイトをご覧ください!
やったこと
試験計画~大量データ準備
「性能試験を実施する」と決まってから、まず初めに以下の三つを実施しました。
- 機能の使われ方を想定する
- 試験前提となる大量データ量の定義
- 性能目標の決定
- 想定する多重度
- レスポンスタイム
- スループット
個人的には、「機能の使われ方を想定する」「試験前提となる大量データ量の定義」部分が最も大変だった記憶があります。
「この機能は1ヶ月に〇〇回利用されるから、1年後にはこのテーブルにはXX件のレコードが貯まる」のようなことを定義していくのですが、Inputとなる情報が少なく、仮説を置きながらの作業になるため、かなり頭を使いました。
どうしても分からないところはプロダクトマネージャー・プロジェクトマネージャーにも手伝って頂きながら、なんとか形にしました。
試験環境の準備(大量データ・試験ツール)
計画を立てたら、次は環境の準備をしていきました。
準備した性能環境用データベースに、前項で定義した大量データをINSERTしていきます。
また試験ツールについては、JavaScriptで書けてGit管理しやすいk6を利用しています。
試験環境の全体像としては、以下のような形になります。(ネットワーク等、細かいところは省略しています)

また、測定に当たってはAPI部分のみを測定することとしています。
試験実施
準備ができたら、いよいよ実際に打鍵による計測を開始します。
試験実施は主に3つのフェーズに分けて実施しました。
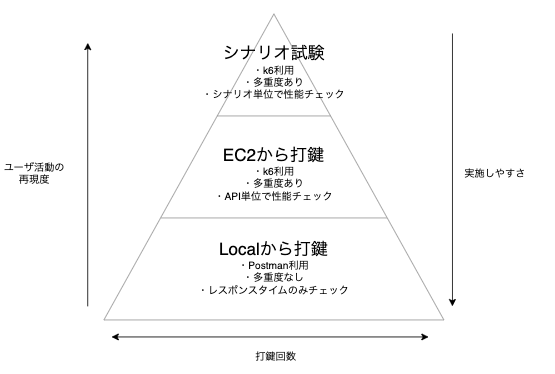
上に行くほどユーザの行動を再現したテストになる分、試験実施にかかるコストが大きくなります。(QAの文脈でよく使われる「テストピラミッド」と似たイメージです。)
それぞれ確認したい観点が異なり、各観点で課題を発見したらその時点で性能改善を実施する運用にしていました。
各フェーズの詳細は以下で述べていきます。
1: Localから打鍵
次項に書いた「k6による性能確認」の前に、Local環境から性能環境に向けて、一度だけ単発でAPIを叩いてAPIのレスポンスタイムをチェックします。
ここでは、「性能目標に比べて、レスポンスが極端に遅いAPIがないか?」を確認します。k6による打鍵だと数分〜数十分掛けて初めて結果が分かる一方、単発での打鍵ならすぐに結果が分かるため、この手順を入れています。
明らかに性能がNGなもの(レスポンスタイムが数十秒かかる、など)についてはここで洗い出し、早めに改善していきます。
2: EC2から打鍵
負荷をかける側のサーバとして用意したEC2にk6をインストールし、いよいよ性能試験を開始していきます。
性能試験では、管理画面に同時接続するユーザの数を想定し、それを元に決定した多重度で性能試験を行います。
主な計測観点は以下の3つです。
k6ファイル例
import { check } from 'k6'; import http from 'k6/http'; export const options = { scenarios: { common: { executor: "constant-vus", //多重度は一定 vus: 10, //多重度10 duration: "10m", //10分間負荷をかける } }, thresholds: { checks: [{threshold: 'rate>0.9', abortOnFail: true, delayAbortEval: '10s'}] //checkを通るRequest数が9割を下回ると失敗強制終了 } }; const apiBaseHeader = {}; //リクエストヘッダ const apiBaseUrl = {}; //負荷をかける対象のURL export default function () { const res = http.get(apiBaseUrl, apiBaseHeader); check(res, {'is status 200': (r) => r.status === 200}); }
k6の結果は以下のように出力されます。

- 10多重で計測
- 全てのRequestがHttpStatus=200でOK
- レスポンスタイム(http_req_duration,95パーセンタイル)は433.3ms
であることが読み取れますね。
3: シナリオ試験
最後に、ある機能におけるユーザの動き(シナリオ)を想定し、複数のAPIを組み合わせた性能試験を実施します。
ここでは、前項より長めに負荷をかけることによって、メモリやCPUなど、インフラリソースの使われ方に異常がないかを主に確認していきます。
ここで取得するメトリクスはGrafanaを用いてダッシュボード化し、一覧できるようにしています。これは過去に、AWS CloudWatchから都度キャプチャを取るのが面倒だった経験に基づくものです。
具体例として、メトリクスのダッシュボード(60分負荷をかけ続けたもの)を以下に載せておきます。

試験を終えて、よかったこと
性能試験~改善の流れが確立し、メンバーに定着した
2月時点では性能試験の経験があるメンバーが少なかったのですが、5月末時点ではほぼ全てのメンバーが性能改善タスクをこなしたことがある状態になりました。
- k6を用いて性能計測をする
- 処理を細分化してどこに性能課題があるか仮説を立てる
- 課題を解決するために設定値やコードを見直して修正、再計測
といった、課題解決の流れを皆で経験/共有できたのはとても有意義だったと感じています。
管理画面の性能指標ができた
この活動以前、Wallet Stationの管理画面には、自社プロダクトとしての明確な性能目標を設定できていませんでした。(もちろん、導入案件単位での性能試験や目標はありました)
しかし現在では、自分達で性能目標を策定する事ができ、自発的な改善活動を続けていくための土台にする事ができています。
また、一通りの計測結果が揃ったため、次回以降の性能試験の参考値となるデータができたのも大きいです。
「推測するな、計測せよ」の言葉通り、改善のためには現状の把握(計測)が必要です。この活動で得られたデータを今後の改善にも生かしていきたいなと思っています。
性能改善事例
「どんな改善事例があったの?」という皆さん向けに、簡単に具体例を載せます。
管理画面リメイク(Backend)における利用技術は、以下です。
- 言語/FW: Kotlin + Spring Boot
- DB: SQL Server
- ORM: JPA + Hibernate + QueryDSL
1. 多対多なテーブルへのアクセスが多い
一覧検索処理において、子テーブルへのアクセスが意図せず複数回飛んでしまい、性能劣化を起こしていたことが何度かありました。(いわゆる「N+1問題」)
主に以下の方針のどちらかで解決できたことが多かったです。
- 子テーブルをJOINして一度にデータを取ってきてしまう
- テーブル設計変更によって子テーブルで管理していた情報を親テーブルに管理させ、子テーブルへのアクセスを不要にする
2. 不要なカラムをSELECTしてしまっていた
管理画面リメイクでは、ドメイン駆動設計(DDD)を導入しています。
DDDを導入している都合上、参照系処理には不要なカラムのデータをDBから取得せざるを得ないクラス設計になっていたことで、結果としてSQLの性能がうまく出ないことがありました。
そこでCQRS(コマンドクエリ分離)の考え方を導入することにしました。
といったクラス設計に変更することで、改善することができています。
CQRSって何?どうして必要になるの?という部分に関しては、以下のブログが参考になると思うので、ぜひ参照してみてください!
3. メモリリークによりFull Garbage Collectionが頻発していた
負荷試験の結果、CPU利用率がずっと100%に張り付いてしまう事象が計測されたため、ECSコンテナの中に入ってtopコマンドを用いて調査したところ、CPUの8割~9割がガベージコレクション(FullGC)に使われていることが分かりました。
ソースコードを見直したところ、根本原因としては「AWS Batch Clientリソースの閉じ忘れ -> メモリが不必要に確保される -> Full GCが頻発」という簡単なものでした。コンテナの中に入りコマンドラインからリソースの利用状況を監視するのは初めてだったので、良い経験となりました。
※ECS(Fargate)コンテナの中に入る際には、以下のECS Execを利用しています。
今後の改善活動
最後に、管理画面リメイクチームにおける、今後の改善活動予定について紹介させてください。
性能課題そのものというより、「性能計測というタスクをより簡単に、継続してやっていく」ための改善内容になっています。
より手軽に検証できる性能環境を作りたい
今回の性能試験では、性能検証ができるインフラリソースが一つしか用意されていませんでした。環境が一つだと、性能検証は並行で進めることが難しいため、別の性能検証が行われている間はタスクに待ちが発生してしまうメンバーが何人かいました。
更なる開発効率Upのため、インフラリソースを増やすことも可能ではあります。ただ、本番運用相当のスペックを持つDBが必要になってくるため、ランニングコストの増加が無視できません。お金の話になってくるので社内調整等も必要になり、逆に開発効率が下がるのではないかという懸念も出てきました。
そこで折衷案として、Local環境にDB含む性能試験用の環境を作成し、Docker Imageとして管理していくことを考えています。
「積めるデータ量は実際のAWS上の性能環境より限られる」「レスポンスタイム/スループットなど具体的な数値計測は最終的にAWS上でやらないといけない」等制約はありますが、自分が行った改善が本当に効いているのかを手軽にチェックするための環境としては有用なんじゃないか、と考えています。
定期的な性能計測の自動化
開発を続けていくにつれて、性能劣化を起こすような修正を意図せず入れてしまう可能性はどうしても無くせません。性能劣化にいち早く気づいて、改善を入れていきたいですよね。
こういったモチベーションから、性能計測をCIに組み込んで自動化する事ができないか、検討中です。
幸い、今回の性能試験で利用したk6はJavaScriptで記載できることからgit管理がしやすいため、GitHub ActionsによるCI運用を考えています。
最後に
2023年2月から5月の間に実施してきた性能試験について、簡単にではありますがまとめてみました。自分含めチームの成長が感じられた4ヶ月だったと感じています。
Wallet Station管理画面は今後も自社オリジナルPayに必要な機能を「使いやすく」提供していきます。
ここまで読んでいただき、ありがとうございました!
インフキュリオンでの開発に興味を持った方は、是非↓のリンクから採用情報にアクセスしてみてください!(Wallet Station以外のプロダクトに関わる枠や、地方在住の方の枠もあります!)